


 Statistical inference definition: the speculation, strategies, and apply of forming judgments in regards to the parameters of a inhabitants and the reliability of statistical relationships, sometimes on the premise of random sampling.
Statistical inference definition: the speculation, strategies, and apply of forming judgments in regards to the parameters of a inhabitants and the reliability of statistical relationships, sometimes on the premise of random sampling.
Put one other means: Burger King serves roughly 16 million individuals a day worldwide. Burger King want to know the important thing drivers to it general gross sales amongst, say, 11 attributes. How a lot wouldn’t it value to ask all of Burger King’s clients after which do the suitable multivariate evaluation? Nicely, let’s determine it prices about $2 per reply, $32 million.
Or Burger King may take a consultant pattern of, say, 1,000 clients for 3 subgroups—a complete of three,000 surveys—and run the identical evaluation. The legislation of statistical inference means that the solutions offered by the pattern of three,000 could be very a lot the identical because the solutions offered by all of Burger King’s clients, inside an error vary of about 3%.
Under is an instance chart the place Burger King has requested 3,000 clients, one from every of the three teams represented on the chart, what they consider 11 attributes.
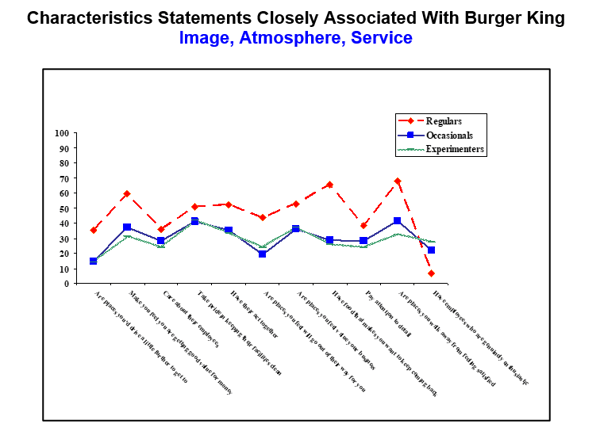 Burger King would then be capable of make selections on advertising and marketing and messaging based mostly on the pattern Regulars, Occasionals, and Experimenters with out having to ask all of the individuals in these classes worldwide. With inferential statistics, you are attempting to achieve conclusions that stretch past the speedy information alone. We use inferential statistics to attempt to infer from the pattern information what the inhabitants would possibly suppose. We use inferential statistics to make inferences from our information to extra normal circumstances via using likelihood fashions.
Burger King would then be capable of make selections on advertising and marketing and messaging based mostly on the pattern Regulars, Occasionals, and Experimenters with out having to ask all of the individuals in these classes worldwide. With inferential statistics, you are attempting to achieve conclusions that stretch past the speedy information alone. We use inferential statistics to attempt to infer from the pattern information what the inhabitants would possibly suppose. We use inferential statistics to make inferences from our information to extra normal circumstances via using likelihood fashions.
Survey analysis and political polling are closely reliant on likelihood fashions. That’s, the projection of the solutions of some onto a whole inhabitants. These tasks are all the time fairly correct as a result of idea of likelihood fashions.
A likelihood mannequin is a mathematical illustration of a random phenomenon. It’s outlined by its pattern house, occasions throughout the pattern house, and chances related to every occasion. The pattern house S for a likelihood mannequin is the set of all potential outcomes. Likelihood is the variety of occasions our final result would prevail.
In different phrases, you could have [your event]/[sum of all possible events]. For instance, while you flip a coin, there are two potential outcomes, heads or tails. If you’re in search of the likelihood of tossing heads, the reply is ½, or 50%. Whenever you roll a cube, the possibilities of rolling a 4 is 1/6, or 16%.
This can be a broad simplification of a fancy definition, however explains why our survey pattern, although consultant of your entire college, is appropriately inside a sure likelihood. Are the solutions from 1000 capable of mission onto a complete pattern dimension of 100,000. The arrogance interval is 3%, so we’re 97% positive that our solutions from the consultant pattern is appropriate.
Let’s transfer on to the accuracy of survey analysis to gauge model fairness, shopper sentiment, political polls, and so on. In these instances we use likelihood samples to get our most correct image.
Likelihood Sampling vs. Non-Likelihood Pattern
A likelihood sampling technique is any technique of sampling that makes use of some type of random choice. With a view to have a random choice technique, you need to arrange some course of or process that assures that the totally different models in your inhabitants have equal chances of being chosen. That’s, if a examine is being accomplished on Wal-Mart customers, and your pattern is Wal-Mart customers, randomly selecting 1000 individuals to survey is an instance of a likelihood pattern. Usually researchers desire likelihood sampling.
The distinction between nonprobability and likelihood sampling is that nonprobability sampling doesn’t contain random choice and likelihood sampling does. Examples of nonprobability sampling embody:
- Comfort, haphazard or unintended sampling – members of the inhabitants are chosen based mostly on their relative ease of entry. To pattern mates, co-workers, or customers at a single mall, are all examples of comfort sampling.
- Judgmental sampling or purposive sampling – The researcher chooses the pattern based mostly on who they suppose could be applicable for the examine. That is used primarily when there’s a restricted variety of those that have experience within the space being researched. For instance, surveying CEOs on the possibilities of their agency buying a personal jet.
- Case examine – The analysis is proscribed to at least one group, typically with the same attribute or of small dimension.
- Panel sampling: Irrespective of how thorough panel information could be, it can’t be thought-about a random pattern as a result of respondents who might qualify for the survey and who usually are not contained within the panel is not going to be surveyed.
- Quotas – A quota is established (e.g. 65% ladies) and researchers are free to decide on any respondent they want so long as the quota is met.
Non-probability and quota samples are quite common in survey analysis. An excellent instance is the phenomena of over-sampling. Lexus want to gauge its company model love story. They take a random pattern of Drivers 18+, asking questions of brand name picture. Then they oversample the important thing demographic, house owners of the car model between the ages of 34-55 – these of us have extra communication worth than the inhabitants at massive. Lexus house owners have a median age of 45 in 2019. They oversample younger, prosperous clients as a result of that’s the market they want to penetrate.
Weighting Ballot Information
Weighting adjusts the ballot information in an try to make sure that the pattern extra precisely displays the traits of the inhabitants from which it was drawn and to which an inference shall be made. Weighting amplifying solutions of individuals beneath represented or decrease voice of these over represented.
Weighting is used to regulate the relative contribution of the respondents, nevertheless it doesn’t contain any adjustments to the precise solutions to survey questions. A great way to look view case weights is to indicate a bunch is [Percentage in Sample Population]/[Sample in Actual Sample].
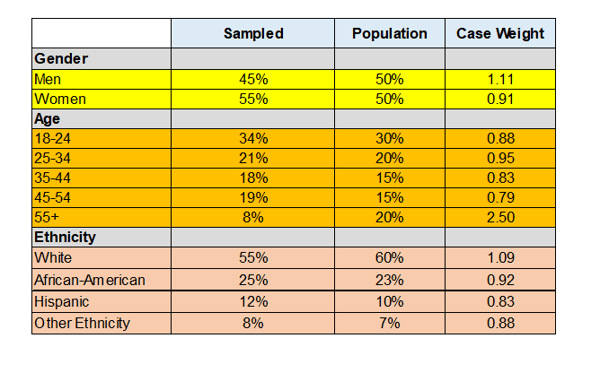
The Desk, beneath, exhibits easy methods to create demographics weights for a examine. In additional refined weighting schemes weight from all three dimensions will be balanced.
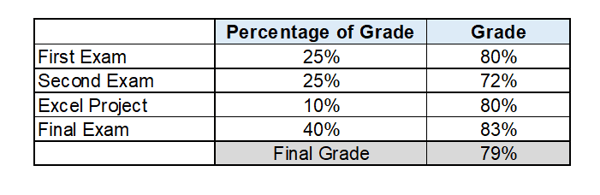
 To show a easy use of weights, beneath is a desk of weighted common, the grading system of a statistics class. The share of grade is, actually, a case weight. The ultimate grade is a weighted common.
To show a easy use of weights, beneath is a desk of weighted common, the grading system of a statistics class. The share of grade is, actually, a case weight. The ultimate grade is a weighted common.
 Non-Response Bias in Surveys
Non-Response Bias in Surveys
Lastly we are going to contact as regards to non-response bias. Nonresponse bias happens when some respondents included within the pattern don’t reply. The important thing distinction right here is that the error comes from an absence of respondents as an alternative of the gathering of misguided information. Most frequently, this type of bias is created by refusals to take part or the lack to achieve some respondents.
Nonresponse is an issue for survey high quality as a result of it virtually all the time introduces systematic bias into the info. This ends in poorer information high quality and may considerably bias any estimates derived from the info. There are a number of methods researchers can use to attenuate nonresponse and to offset the bias it introduces into information. In the course of the information assortment interval, researchers can use:
- Name backs
- Incentives
- Oversampling
- Weighting Up recognized Non-Response Teams.
When designing a examine, statistical inference, likelihood modeling and weighting very important for methodological and moral causes, in addition to for causes monetary assets
The understanding of the phrases and results of the themes coated on this temporary abstract can construct an understanding and basis within the subject of empirical survey analysis.

Editor’s be aware: Michael Lieberman is founder and president of Multivariate Options, a New York consulting agency providing complete statistical consulting. He will be reached at 646-257-3794 or at michael@mvsolution.com.

{kind=link}