

Studying Time: 10 minutes
Why Is Actual-time Knowledge Ingestion Essential for B2C Manufacturers?
MoEngage is an enterprise SaaS enterprise that helps B2C manufacturers collect invaluable insights from their buyer’s conduct and use these insights to arrange environment friendly engagement and retention campaigns.
As these campaigns and insights are primarily based on the top customers’ interactions (shoppers), essentially the most vital requirement is to have the ability to ingest all of this demographic and interplay knowledge and make it accessible to varied inner companies in a well timed style.
Because the enterprise has grown during the last years, we’ve got been lucky to have the ability to assist prospects the world over to realize their advertising objectives. With companies turning into more and more digitized, our prospects themselves have seen progress of their buyer base at an exponential price. They’ve now come to count on extremely responsive purposes, which might solely be attainable if their knowledge will be ingested in real-time.
Overview of MoEngage’s Knowledge Ingestion Structure
When ingesting knowledge, the database turns into the most important bottleneck. MoEngage makes use of MongoDB for many of its database use circumstances. Whereas some databases can help larger write throughput, they’re unable to help querying utilizing varied filters as they’re primarily key-value shops. We have now spent appreciable time fine-tuning our clusters. Indexing, sharding, and occasion right-sizing are among the many many optimizations we’ve got in place. Nonetheless, these aren’t sufficient to make sure real-time ingestion. Thus, our purposes have to be designed to be able to obtain a bigger scale of reads and writes.
What high-level method did we take to resolve this?
One of many strategies that may dramatically enhance the size of writes is using bulk writes. Nonetheless, utilizing it’s tough as any shopper’s exercise is approaching the fly, and processing its knowledge requires entry to its newest state for us to have the ability to do constant updates. Thus to have the ability to leverage it, we want a messaging layer that permits partitioning knowledge in a approach that any given shopper’s knowledge would at all times get processed by just one knowledge processor. To try this, in addition to obtain our aim of ordered knowledge processing, we determined to go for Kafka as a pub-sub layer. Kafka is a widely known pub-sub layer that, amongst different issues, helps key options corresponding to transactions, excessive throughput, persistent ordering, horizontal scalability, and schema registry which might be very important to our skill to scale and evolve our use circumstances.

MoEngage’s real-time knowledge ingestion helps manufacturers ship customized messages to their prospects on the proper time
The following little bit of perception was that to be able to leverage bulk writes, quite than utilizing the database as a supply of reality, we wanted a quick caching layer as a supply of reality, permitting us to replace our databases in bulk. Our expertise with DynamoDB & ElastiCache (redis) taught us that this is able to be prohibitively costly. Because of this, the caching layer that we’d use must be an in-memory cache. This could not solely decrease the price of operating the cache however would result in giant beneficial properties in efficiency as nicely. Probably the most distinguished key-value retailer for this use case is RocksDB which might leverage each the reminiscence of an occasion in addition to its disk ought to the quantity of information saved overflow the reminiscence.
Our determination to make use of RocksDB and Kafka introduces new challenges as what was once a stateless system would now develop into a stateful software. Firstly, the scale of this RocksDB cache can be within the order of tons of of gigabytes per deployment, and the appliance leveraging it may restart as a consequence of varied causes – new characteristic releases, occasion termination by the cloud supplier, and stability points with the appliance itself. The one solution to reliably run our software can be to trace the offsets at which we final learn knowledge from Kafka and maintain that in alignment with the state of the contents of our cache. This aggregated state would have to be continued externally to permit for restoration throughout deliberate or unplanned restarts. Above all, we would wish a excessive stage of configurability for this complete checkpoint course of (frequency, the hole between checkpoints, concurrent checkpoints, and many others.). Slightly than constructing the whole resolution in-house, it was extra prudent to leverage current frameworks as they might have higher efficiency, reliability and neighborhood help. We evaluated varied streaming frameworks and concluded that Apache Flink can be the one with all of the options and the specified efficiency at our scale. At a excessive stage, a flink job consists of a number of activity managers who’re liable for executing varied operators that implement the information processing necessities of the appliance. The job of allocating duties to activity managers, monitoring their well being, and triggering checkpoints is dealt with by a separate set of processes referred to as job managers. As soon as the duty managers resume knowledge processing, any consumer state will get saved in a finely tuned RocksDB storage engine which will get periodically checkpointed to S3 and Zookeeper to be able to facilitate swish restarts.
How did we put all of it collectively?
After determining the suitable language, framework, and messaging layers, the time got here to start out constructing out the system and migrating all our current options. Our ingestion layer consists of 4 steps:
- Knowledge validation layer that intercepts buyer knowledge by way of varied sources
- Inner schema administration and limits enforcement for all of the consumer, machine, and occasions and their properties which might be tracked throughout prospects in addition to customer-specific properties
- Utilizing the identifiers within the incoming requests to fetch, probably create and at last replace the state of customers and their units
- Enriching the incoming interactions that had been carried out by an finish consumer with particulars in regards to the consumer that we internally retailer about them and making them accessible to different companies
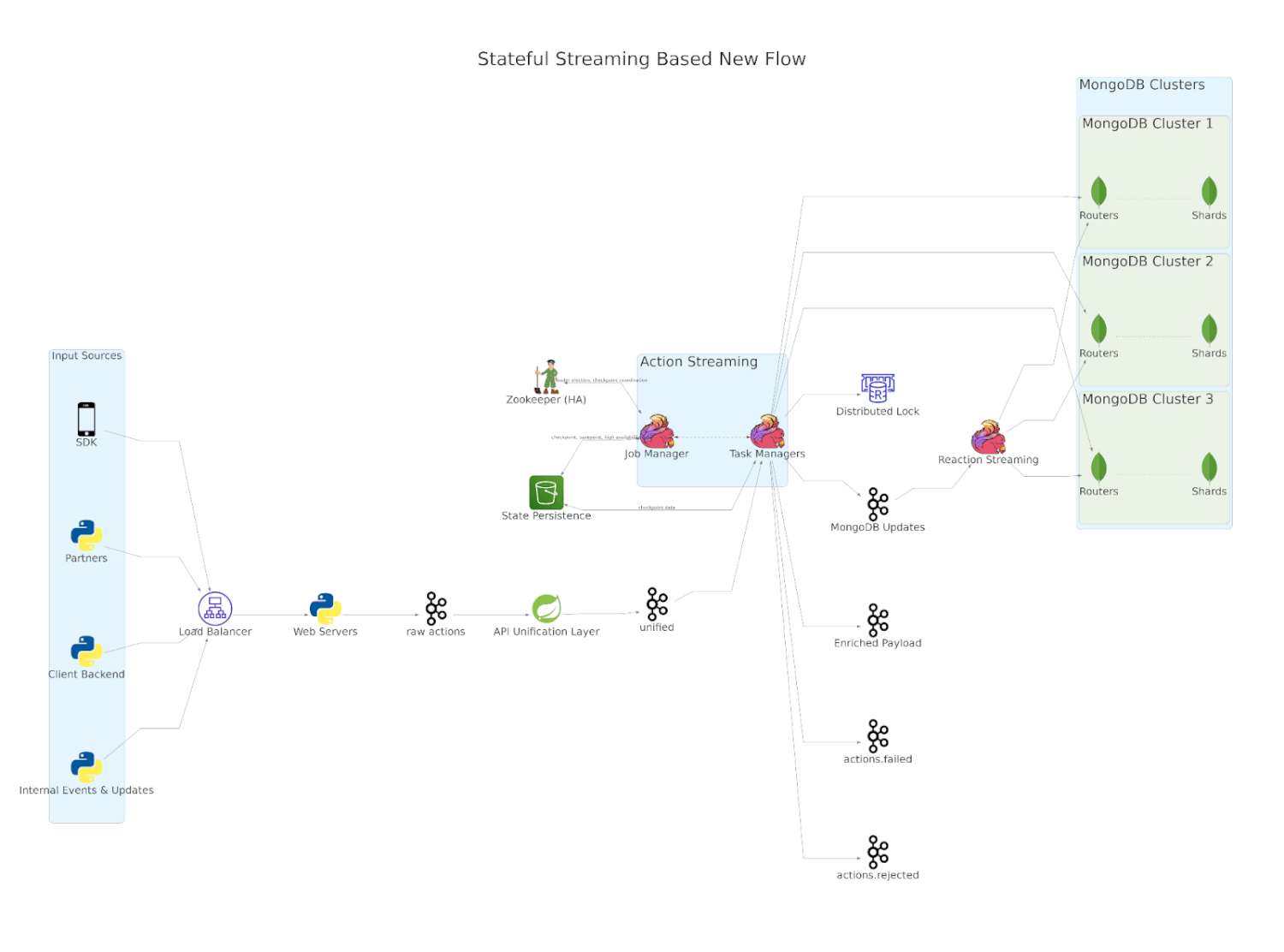
API Unification Layer
As knowledge validation and schema administration aren’t actually tied to any specific consumer however quite to a consumer, we determined to carve these options out as a devoted service. Moreover, as we talked about earlier, knowledge can come from varied sources, together with cell SDKs that we offer, knowledge API to publish the identical by way of the purchasers’ backend, third-party companions corresponding to Section, advert attribution companies, CSV recordsdata, and inner APIs. As every of those was focusing on totally different use circumstances, through the years, the implementations for ingesting knowledge throughout these sources had diverged although the last word aim was to replace the state of customers and their units. We took this chance to consolidate the conduct throughout sources inside this knowledge validation layer and rework every of those inputs into one consolidated output stream that might function enter to companies that implement the remainder of the performance.
Motion Streaming
Probably the most vital service is the one which offers with consumer & machine creation in addition to occasion processing. With knowledge validation and API variations taken care of within the upstream layer, this service depends on the identifiers of customers and units within the consolidated payload to find out what consumer and machine which may have been concerned, which could typically contain creating their entries and on different events contain merging and even elimination of current paperwork. The latter can occur as a result of, in our enterprise area, each customers and units can have a number of identifiers, and there’s no single identifier for both that’s leveraged by all enter knowledge sources. As soon as the entities are resolved, the following part of this flink job is to course of all of the occasions throughout the payload, the processing of which can lead to a change within the state of the consumer or the machine concerned. Slightly than updating their states straight, it determines the change in state and publishes them to Kafka for use by one other downstream service to replace entities in bulk. We’re capable of decide the change in state because the job depends on RocksDB because the supply of reality. Thus RocksDB not solely helps us reduce down our database reads by greater than half, however extra importantly, it permits us to leverage bulk writes to databases.
Response Streaming
The ultimate service in our pipeline is a comparatively easy service that consumes MongoDB replace requests from Kafka and applies them in bulk, thereby drastically rising the write throughput of our database clusters. With RocksDB serving as a supply of reality, we will leverage full non-blocking and asynchronous I/O to do our updates which helps us drastically enhance our effectivity of writes. Not solely will we do extra writing, however we’re capable of do them with far fewer assets! We did should spend a while constructing a buffering mechanism that ensures that any entity has just one replace in-flight at any given time, with out which the order of write operations can by no means be assured.
MoEngage’s real-time ingestion infrastructure helps manufacturers drive extra ROI from their engagement, retention, and monetization campaigns
Fault tolerance of our system
Splitting our ingestion layer into three totally different jobs helped us obtain the effectivity that we wished, however this got here at the price of better possibilities of failure. Any one of many companies may go down as a consequence of a change in code or stability points inside our cloud. Checkpoints may help us keep away from re-processing all the knowledge in our messaging layers, however it doesn’t get rid of the possibility of duplicate knowledge processing. That is why it was vital to make sure that every service was idempotent.
Response streaming was designed to help solely a choose set of write operations – set, unset, including to a set, and eradicating from a set. Any consumer intending to make use of this service would wish to leverage a number of of those operations. This set of 4 operations has one factor in widespread – the repeated software of any of those on a doc will finally produce the identical end result.
API Unification Layer & Motion Streaming each depend on Kafka transactions to make sure that even when knowledge will get processed a number of instances, it isn’t made accessible to downstream companies till the checkpoint completes. Care can be taken to make sure that all time-based properties have steady values regardless of restarts and making certain that no report older than these instances ever will get re-processed.
Deployments & configuration
Our system is designed to have the ability to run each as containerized purposes in Kubernetes in addition to on cloud present digital machines, which MoEngage has traditionally relied on. That is to make sure enterprise continuity whereas all of the kinks of our Kubernetes setup get sorted out, in addition to all engineers have a adequate understanding of it. The power to spin up containers in milliseconds can’t be matched by digital machines. Kubernetes manifests for workloads the world over are managed utilizing customise, which makes it straightforward to keep away from any kind of configuration duplication. Deployments outdoors of Kubernetes are managed utilizing Terraform, Terragrunt, and CodeDeploy with in-house enhancements to make it straightforward to spin up new deployments, whereas configurations are managed utilizing Consul. We use HOCON because the format for configuration as they permit for the straightforward composition of a number of configuration recordsdata into one, thereby permitting us to interrupt configuration into small reusable chunks that can be utilized throughout deployments and for a number of companies, making it straightforward to make large-scale modifications in configurations. It additionally offers the power to supply configurations by way of items, eradicating any kind of ambiguity within the worth of a configuration.
Learnings and Key Takeaways
Scala – Java interoperability
We applied our system by leveraging the precept of layered structure – enterprise logic fully freed from any infrastructure dependencies, a service layer that interacts with exterior programs and invokes the enterprise logic, and at last, the splitting of this service throughout varied Flink operators tied collectively by a job graph. Enterprise logic was applied in Java as we felt that hiring or coaching builders in Java can be simpler whereas the comparatively static parts of the system had been written in Scala in order to leverage the advantages of Scala’s sort system, skill to compose features, error dealing with capabilities, and light-weight syntax. Nonetheless, this determination proved to be a design blunder as we couldn’t absolutely leverage the most effective capabilities of both language.
Had we written our code completely in Scala, we may have:
- Leveraged property-based testing together with refined varieties to considerably scale back the burden of testing the whole codebase
- Leveraged an impact system corresponding to ZIO/Cats Impact as a substitute of working with vanilla Scala Future and Attempt, which is commonly more durable to check
- Not have needed to take care of generally encountered exceptions in Java by leveraging Scala’s superior sort system
Had we written our code completely in Java, we’d have:
- Leveraged the SpringBoot ecosystem to construct out our service layers
- Prevented express separation of area and persistence fashions as Java lacks libraries to robotically convert one to a different, and Scala libraries don’t at all times work with Java POJOs
Operating Flink jobs is extra work than we thought
Whereas Flink does provide nice options that do certainly work at our scale, its characteristic set is commonly missing in varied features, which leads to extra developer effort than deliberate. A few of these weaknesses aren’t typically nicely documented, if in any respect, whereas some options require fairly a little bit of experimentation to get issues proper
- It’s fairly widespread for varied Flink libraries to interrupt backward compatibility, which forces builders to always rework their code in the event that they want to leverage newer options
- Flink additionally helps varied helpful options corresponding to auto-scaling, precisely as soon as semantics, and checkpoints which require numerous experimenting to get proper with little steering on selecting the best way to choose the suitable set of configurations. That mentioned, the neighborhood could be very, very responsive, and we’re grateful for his or her assist in our journey
- Integration testing of flink jobs is just about unimaginable, given its resource-intensive nature. Unit testing is feasible however is quite cumbersome. We might counsel builders maintain virtually no logic within the Flink operators themselves and merely depend on them for knowledge partitioning and state administration
- Schema evolution doesn’t work when the courses leverage generics, which is sort of at all times the case. This pressured us to spend time writing our personal facet logic. What additionally caught us off-guard was that even newer Java options, corresponding to Non-obligatory, may cause schema evolution to not work
- We wished to leverage the published operator to simplify configuration administration. Nonetheless, since enter streams from different sources may fireplace independently, we ended up not utilizing this resolution. It will be good to have a signaling mechanism amongst operators.
- Over time, we’ve hit fairly a number of stability points when working with Zookeeper and Kafka which turned out to be respectable bugs of their codebase. Most of them have now been mounted however we’ve needed to face numerous manufacturing points and constructed fast workarounds within the meantime.
MoEngage always strives to make enhancements to the platform that helps manufacturers ship seamless experiences to their prospects
Future Enhancements
There are a number of enhancements that we plan to work on within the coming months, a few of that are:
- We’re now at a stage the place we’re satisfied that we’ve hit the bounds of MongoDB and, after a number of years, might want to discover an alternate retailer for consumer and machine properties that may help a lot larger write throughput whereas MongoDB itself can be leveraged for its indexes
- Flink’s checkpoint mechanism requires the job to be a directed acyclic graph. This makes it unimaginable to alternate state inside sub-task of the identical operators. Whereas that is very nicely documented, it’s a characteristic that we want, and we’ll discover Flink’s sibling undertaking Stateful Features, which doesn’t have this limitation
- Flink’s just lately launched Kubernetes operator can deal with the whole software lifecycle, which supplies higher management over checkpoints and savepoints than our personal in-house developed resolution, and we plan to change it sometime
- Using Kafka makes it tough to implement rate-limiting insurance policies as we’ve got 1000’s of consumers whose knowledge is distributed among the many partitions of a subject and Kafka itself can’t help one subject per consumer at our scale. We are going to discover alternate pub-sub layers, corresponding to Pulsar and Pravega, that provide better flexibility on this regard
- We thought of leveraging OpenTelemetry for end-to-end metrics and log-based monitoring and distributed tracing throughout companies; nevertheless, it has solely just lately moved out of alpha. We are going to discover this additional as an end-to-end monitoring resolution
Conclusion
We got down to guarantee real-time ingestion of our prospects’ knowledge always at a scale that exposes the issues of the most effective open-source frameworks. It was an incredible problem to have the ability to be taught and develop into adept at a number of languages and frameworks, and we’ve totally loved knocking them off one after the other! When you’re occupied with fixing related issues, take a look at our present openings within the Engineering workforce at MoEngage!
The submit How MoEngage Ensures Actual-time Knowledge Ingestion for Its Clients appeared first on MoEngage.

{kind=link}